The War Stories Behind P**’s Distributed Training
28 Aug 2019Setting the Scene
In 2018, I was leading distributed training efforts for Company P’s Ads ML team.
Our ads retrieval and ranking models were exploding in complexity, fed by 120TB of training data. Training runs stretched beyond a full day, which meant iteration cycles slowed, experiments backed up, and our ability to improve ads relevance was bottlenecked.
For a platform where ad revenue depends on real-time personalization, waiting 24 hours to validate an idea was unacceptable. We were keen to make training fast enough to keep up with the business.
First Push: Scaling Out
We started with data parallelism using TensorFlow’s parameter server (PS) setup. On paper, it looked promising: multiple workers training in parallel, gradients aggregated centrally, faster iteration.
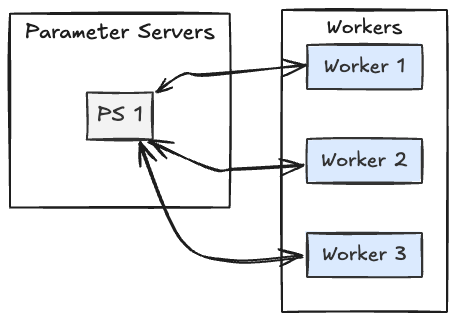
Figure 1: Workers push gradients to parameter servers, which update and broadcast weights.
In practice:
- GPUs sat idle while network bandwidth maxed out.
- Training diverged with NaN losses beyond a few workers.
- Async updates silently degraded accuracy.
Instead of speeding up, distributed training had become a minefield.
Battle #1: The Bandwidth Bottleneck
Adding GPUs didn’t help — it slowed training. Embedding lookups were saturating network bandwidth between workers and PS. GPUs weren’t the bottleneck — the wires were.
Fix: we restructured variable placement and optimized embedding communication. GPU utilization improved, but failures appeared further down the pipeline.
Battle #2: The NaN Nightmare
Everything was stable — until it wasn’t. Sporadically, our retrieval model produced bizarre predictions much greater than 1 during training and inference.
Our retrieval model was a simple two-tower DNN (user tower + ad tower). If outputs to the sigmoid were blowing up, the culprit had to be the embedding layer.
Step 1: Forming the Hypothesis
The logic was simple: the sigmoid only outputs 1 if its input is extremely large. That suggested the embedding vectors themselves were exploding.
We validated by dumping the max norm of the embedding matrix:
latest_model = tf.train.latest_checkpoint(FLAGS.model_path)
tf.train.Saver().restore(sess, latest_model)
for v in tf.trainable_variables():
if v.name.startswith("embedding"):
value = sess.run(v)
norms = np.linalg.norm(value, axis=1)
print("MAX NORM: ", value[np.argmax(norms)])
Sure enough, we saw embedding values spiking into the hundreds:
MAX NORM:
[ 119.235 -3.0620162 11.270749 -110.523285 22.60
-23.46 7.710512 -8.456131 93.042046 3.8611507
-86.27594 122.26015 -3.9738152 97.36309 -0.32378
47.52777 -33.67306 2.09686 42.772686 4.325833
-13.735 83.2778 -191.951727 -21.930279 -23.161955 ]
Step 2: Controlling the Variables
The next question: was this a fundamental bug or specific to distributed training?
With one worker, values looked normal:
MAX NORM: [0.44, 0.52, -0.05, 0.30, ..., 0.17]
With two workers, the values suddenly spiked after ~26k steps:
MAX NORM: [-15.92, 16.45, 27.94, ...]
And TensorBoard metric confirmed it: loss and accuracy collapsed abruptly after 26k steps. This wasn’t a slow gradient explosion — it was a sudden instability triggered by distributed training.
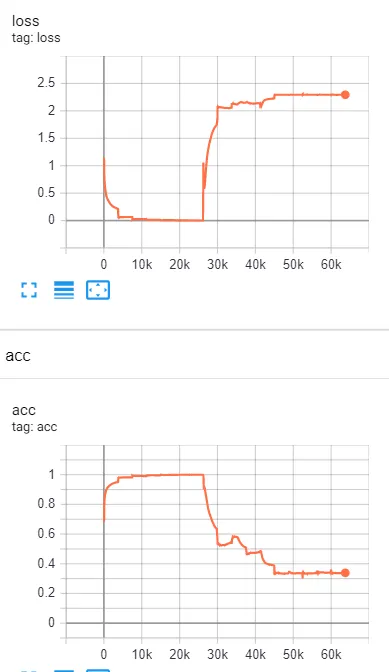
Figure 2: Training metrics from Tensorboard. The loss and acc become bizarre after 26k steps
Step 3: Digging into the Parameter Server
The async PS setup created two problems:
Race conditions — TensorFlow’s use_locking=1 only guarded individual variable writes, not entire update blocks. Adam’s momentum states were updated concurrently by multiple workers, making it not thread-safe.
Gradient staleness — At time T=100, one worker might send a gradient from step 50, another from step 75, another from step 100. Aggregating them produced a gradient pointing in the wrong direction.
Momentum amplified the issue: large gradients increased staleness, pushing weights further off course. In extreme cases, the aggregated gradient pointed in the opposite direction of descent.
Step 4: The Pragmatic Fix
The theoretical fixes (critical sections, optimizer refactoring) were interesting, but the pragmatic solution was clear: switch to synchronous training.
- All workers computed gradients in lockstep.
- The PS applied updates only after collecting all contributions.
- Per-step latency rose, but convergence stabilized.
With this change, our model trained reliably — no more NaNs, no more divergence.
Battle #3: Delivering Impact
With the new pipeline, training time dropped from 24 hours to 4 hours on the 120TB dataset.
That speedup unlocked:
- 3× more experiments per week
- Stable convergence for large deep learning models
- Production readiness for scaling retrieval and ranking systems
This infrastructure directly enabled 2–3% revenue lift (millions of dollars annually).
Reflections
What I learned is that distributed training success isn’t about “which framework” — it’s about debugging, iteration speed, and pragmatic trade-offs.
Key takeaways:
- Optimize the system, not just the math — bandwidth and placement matter.
- Monitor embeddings early — they’re the canaries of instability.
- Sync beats async in production — slower steps are fine if models converge.
- Tie infra wins to business outcomes — faster training → faster experiments → real revenue.
Closing
That journey taught me that making ML infrastructure production-ready is about more than algorithms. It’s about navigating the war stories, aligning infra and product goals, and delivering results the business feels.
It’s one thing to understand distributed training in theory. It’s another to lead the charge to make it real at scale.
Disclaimer: These are my personal opinions only. Any assumptions, opinions stated here are mine and not representative of my current or any prior employer(s).